Azure Container Apps – scaling, is the most powerful feature of this service. You have the option of scaling your application from 0 to 300 instances! Awesome. You may view all of the series’ articles here.
There are three scaling rules that can be used; let’s go over them briefly:
- HTTP: Based on the number of concurrent HTTP requests to your revision.
- TCP: Based on the number of concurrent TCP connections to your revision.
- Custom: Based on CPU, memory, or supported event-driven data sources such as:
- Azure Service Bus
- Azure Event Hubs
- Apache Kafka
- Redis
Unfortunately, there is no option to use Terraform to set Azure Container Apps scaling, you can use AzApi to do this, but personally, I’m not too fond of this possibility. Rather, I would use PowerShell as a simpler and easier method. When the AzureRM provider provides the possibility of scaling definition, I will create a new article.
In my tests, I utilized the HTTP rule, which is defined below:
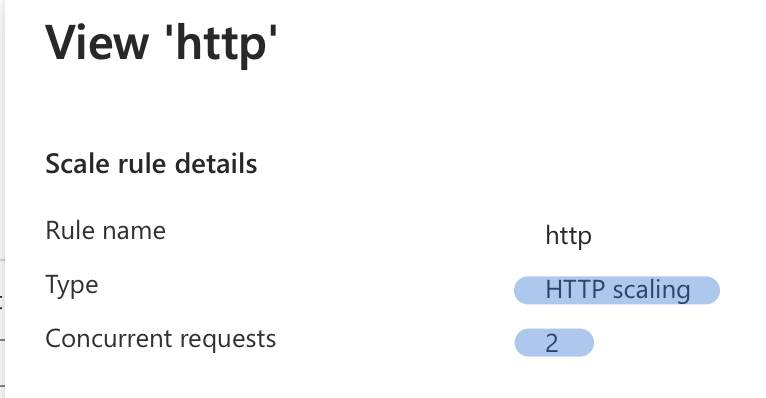
When app scale-up criteria are met, then replica is added, until the criteria are satisfied. To scale down two criteria must be met. First, is scale-down criteria, so in my case, the concurrent requests rate drops. Second is ‘Scale down stabilization window’ time is reached, the default is 300 seconds. You’re probably wondering how quickly this replica will be ready for ingestion after dropping to zero. I ran the tests to see how it works.
From freeze to running application – test
I ran the following test to see how long it takes to execute your workload after replica scaling to zero:
- Set the scale rule from 0 to 5 replicas.
- Execute HTTP GET requests, when the replica is zero (scale down after 300 seconds, of the last request)
- Run in Consumption mode.
The results of the tests are shown below:
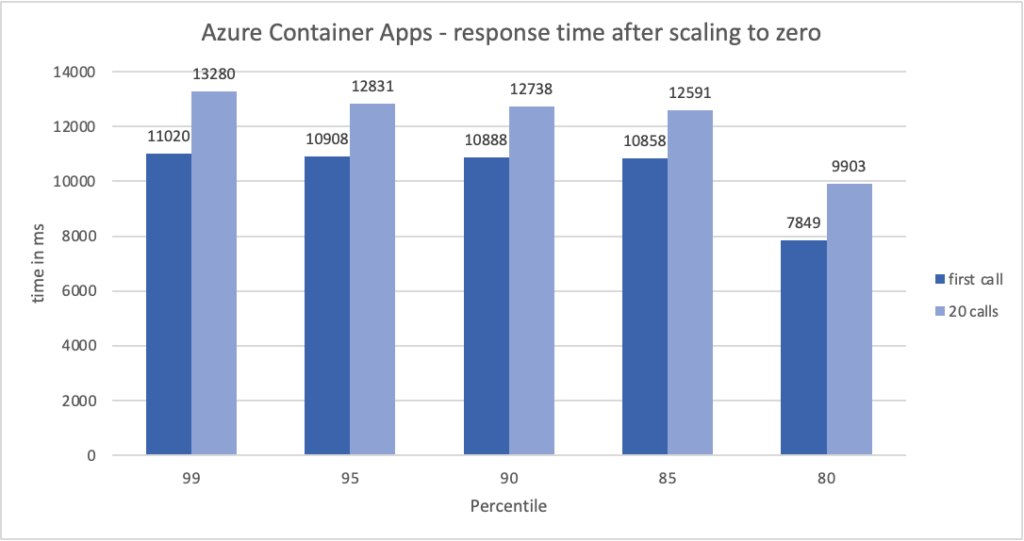
Two types of metrics are shown in the diagram above:
- first call – time for the first call to complete, with no replica running.
- 20 calls – the sum of time for 20 calls to complete.
As you can see, the initial call takes up the majority of the time. Nevertheless, this is an excellent result for run-up frozen resources. The average time for the first call is 7670 milliseconds. On the other hand, handling a single request, excluding the initial call, takes 90 milliseconds. So if we want to save money on running the instance, we must accept a longer first request after the freeze. This 7 seconds is not a long time for a spinup app from my perspective, hence I would definitely utilize it in development, test, and QA environments. If I’m operating a production application, though, I’d rather pay more for at least one running duplicate.
If in your case this time is too high, you need to set the replicas to 1, and then your app will run all the time.
I sincerely hope you enjoyed it, and if so, I’d appreciate a Like or Comment on my LinkedIn profile.
Here you can find all the articles from the series.